Empfohlenes Buch: Aurelien Geron, Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
Github mit den Beispielen: GitHub - ageron/handson-ml2: A series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in Python using Scikit-Learn, Keras and TensorFlow 2.
Oder: https://www.deeplearningbook.org
Übersicht: Machine learning - Wikipedia
Software
Python mit
- scikit-learn
- tensorflow
- scipy
- numpy
- pandas
Was ist KI?
Eine Sammlung von oft statistischen Ansätzen, um Zusammenhänge in Daten zu finden. Dabei wird vorausgesetzt, dass die Daten schon verarbeitet sind (Parameter bzw. Feature extraction).
Eingabedaten: Tabelle mit Parametern (Werte, die die Daten beschreiben) → Lösung

Bei Neuronalen Netzen (NN) wird die Funktion des menschlichen Nervensystems mathematisch nachgebildet. Es können Auswertefunktionen in das Netz eingebunden werden (Convolution, Faltung), so dass Sensordaten nicht vorverarbeitet werden müssen.
Eingabedate:
Fully-connected layer: Tabelle mit Parametern (Werte, die die Daten beschreiben) → Lösung
CNN: Analoge Signale, Bilder, Videos, …
Schlagworte
Supervised vs. unsupervised: Man gibt die Lösung vor vs. es das Modell muss selber Lösungen finden
Reinforcement learning: Das Modell macht zufällig Sachen und bekommt ein Feedback, ob es gut oder schlecht war.

Classification vs. Regression: Ergebnisse sind Klassen vs. genaue Werte. Scheint Morgen die Sonne oder gibt es Wolken? vs. ist es Morgen 20.0°C, 20.1°C, 20.2°C, …?
Online vs. offline: Daten werden in Echtzeit generiert vs. dar Datensatz liegt als Datei vor.
Transfer learning: Ein NN wird mit Daten trainiert. Einige Layer werden eingefroren (es ist kein Training mehr möglich) und wird dann mit anderen Daten trainiert. Das Modell wird auf einen Anwendungsfall trainiert und dann auf einen anderen übertragen. Meisten werden die CNN, LST, RNN Layer eingefroren und nur die fully-connected layer neu trainert.
Anomaly detection: Die KI lernt wie gute Messwerte aussehen und kann erkennen, wenn die aktuellen Messwerte weit von den guten abweichen.
Deep AI: KI, die ein Bewusstsein hat und moralische Entscheidungen treffen kann. Nur für SciFi Literatur interessant. In realen Anwendungen aktuell nicht relevant.
Ansätze
Fuzzy Logic
Ursprung der ML Ansätze. Daten werden verarbeitet und Parameter werden bestimmt. Dann wird Anhand der Parameter eine Lösung gebildet.
Beispiel: Eine Bohrmaschine wird mit einem Mikrofon überwacht. Aus den Sensordaten wird die dominante Frequenz bestimmt. Aus Versuchen hat sich ergeben, dass die Frequenz normalerweise um 5kHz liegt, aber auf 10kHz steigt, wenn die Maschine nicht richtig behandelt wird. Nun lässt sich mit folgendem Pseudocode eine Warnsoftware gestalten:
if Frequenz < 7500:
alles_gut()
else:
stopp()
Die Grenze wurde mit 7.5kHz einfach in die Mitte der beiden Frequenzen gelegt.
Um diese Grenze besser zu bestimmen oder das System genauer zu machen sind mehr Sensoren und Messungen notwendig. Es können natürlich auch mehr als 1 Parameter aus den Sensordaten berechnet werden. Nutzt man z.B. 1 Mikrofon, 1 3-Achsaccelerometer und 1 Strommessung aus denen man jeweils 20 Parameter bestimmt, erhält man 5*20=100 Parameter. Man hätte also eine if-else Orgie, in der 100 Werte geprüft werden müssen.
Damit man das nicht von Hand machen muss gibt es bessere Ansätze.
Machine Learning - Statistisch (scikit-learn)
Grundgedanke wie beim Fuzzy Logic, aber alles wird anhand der gegebenen Daten eigenständig berechnet.
Random Forest Classifier
Aus den Parametern und Schwellwerten wird ein zufälliger Entscheidungsbaum generiert.
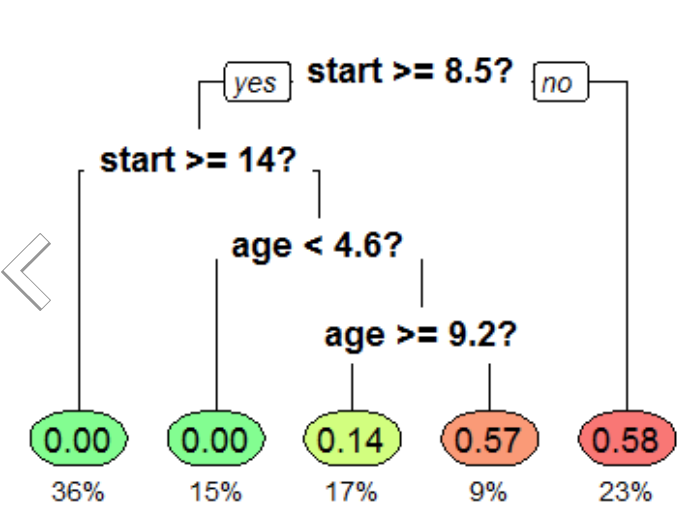
Um das Ergebnis zu verbessern wird nicht nur 1 Baum, sondern mehrere berechnet (Wald). Das am meist genannte Ergebnis der einzelnen Bäume ist das Ergebnis des Waldes.
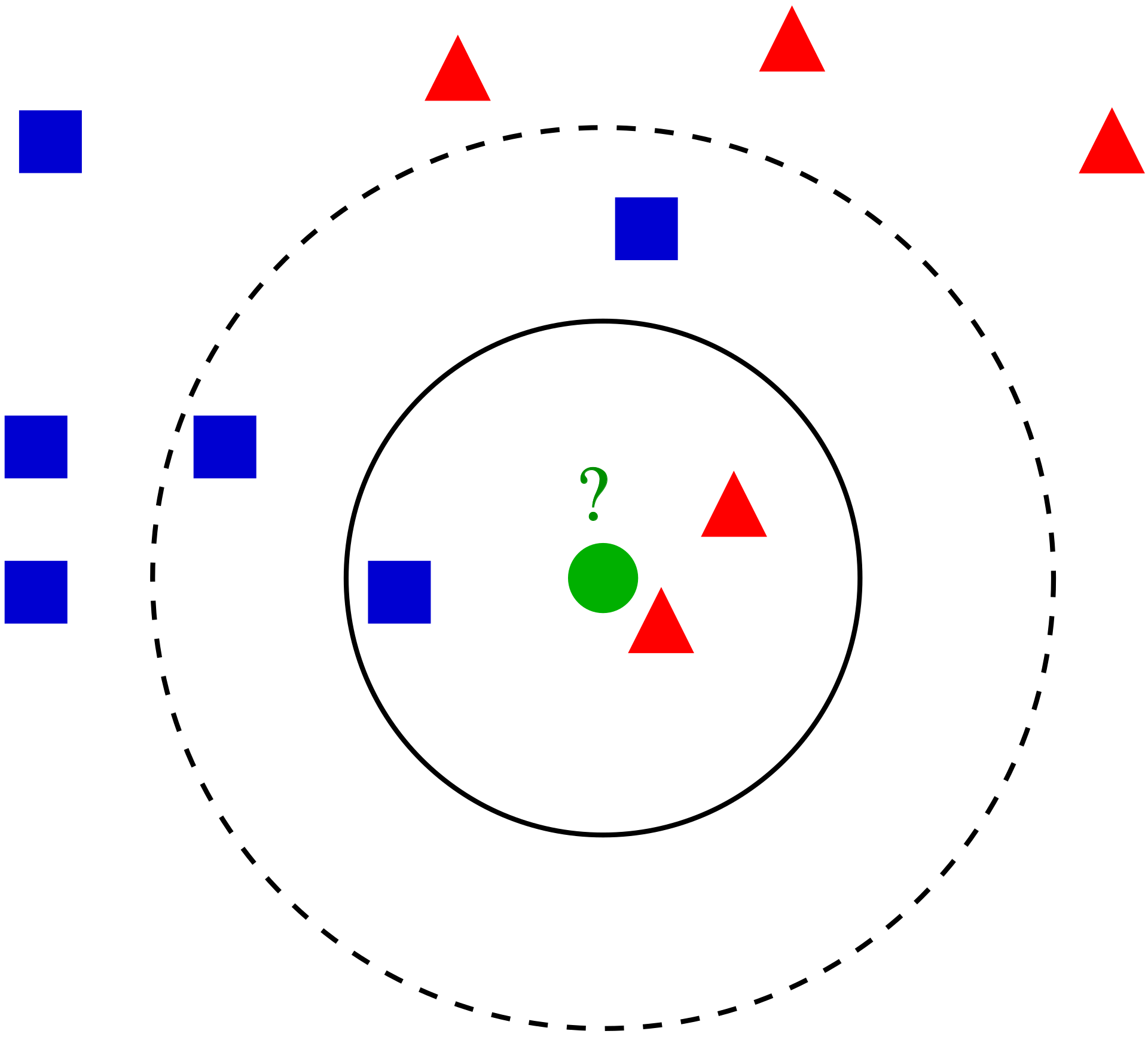
K-nearest neighbor
Die Daten werden in einem X-dimensionalem Diagramm angeordnet, wobei die X die Anzahl der Parameter ist. Bei neuen Datenpunkten wird gezählt, welcher bekannte Punkt am meisten in der nähe liegt.
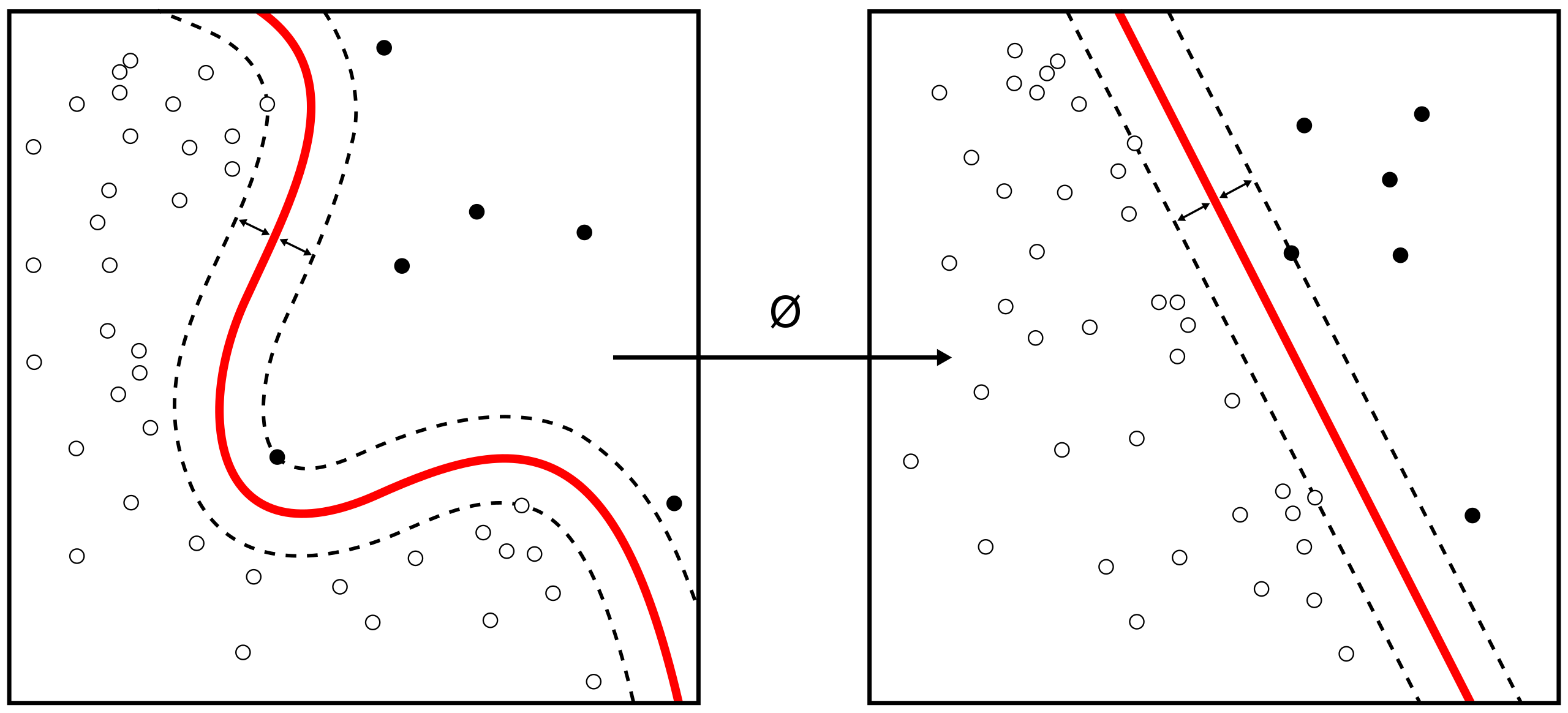
Support Vector Classifier
Die Daten werden in einem X-dimensionalem Diagramm angeordnet, wobei die X die Anzahl der Parameter ist. Aus diesen Daten werden die Grenzen bestimmt. Vorteil gegenüber KNN: Nicht-lineare Verhalten können abgebildet werden. Bei neuen Datenpunkten wird geprüft, auf welcher Seite der Grenzen der Datenpunkt liegt und somit welche Kategorie er zugeordnet wird.
Deep Learning - Neuronale Netze (Tensorflow)
DNN / fully-connected layer

DNN bestehen aus einem Input Layer, mehreren Hidden Layern und einem Output Layer. Das Output Layer wird über die z.B. softmax Aktivierungsfunktion berechnet. Das Neuron mit der höchsten Zahl entspricht dann der der Daten zugeordneten Kategorie.
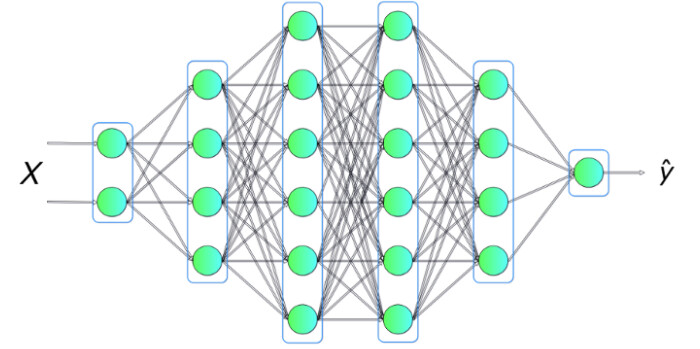
Für jedes Neuron in den Hidden Layern wird für jeden Input ein Koeffizient und Bias berechnet. Der Output ist eine Zahl.
CNN / convolutional layer

Berechnet eine Faltung mit einem oder mehreren Kernel. Die Kernel werden dabei von einem Algorithmus eigenständig bestimmt und optimiert. Der Output ist ein Array von Anzahl Kernel x Verschiebungsschritte Kernel mit Zahlen die angeben, wie gut der Kernel an der Stelle in das Eingangssignal passt. → Mustererkennung und wo wird welches Muster in einem Audio- bzw. Bildsignal erkannt.
Weitere Auswertung und Ergebnisbildung über fully-connected layer.
RNN / recurrent layer
Sucht eigenständig wiederkehrende Muster in Signalen über Erinnern/Vergessen. Dynamischer als CNN, aber mehr Rechenaufwand.
Weitere Auswertung und Ergebnisbildung über fully-connected layer.
GAN / General Adversarial Networks
Können neue Daten anhand von Trainingsdaten schaffen.
Es werden 2 Netzte trainiert. Eines, was z.B. Boote in Bildern erkennt, und eins, welches neue Bilder mit Booten anhand von bekannten Bildern erstellt. Das Ziel des erstellenden Netzes ist es, das prüfende Netz davon zu überzeugen, dass ein Boot im Bild ist.
Hilfslayer
Pooling, Dropout, Concatenate, Flatten, …